By W.H.L. and Claude (Sonnet 5)
Champaign Magazine Series on Gradual AGI #4
Abstract
Prior work in this series proposed Ceiling, Floor, and Slope as vocabulary for the rate at which societies assimilate advancing AI capability, reframing “Gradual AGI” as a civilizational assimilation rate rather than a single capability threshold. That vocabulary was descriptive: it named a gap without deriving its dynamics. This paper develops a minimal discrete-time dynamical specification of the same problem — a recurrence over the Ceiling-Floor gap with derived fixed points and stability conditions, a threshold-gated coupling between capability and adoption, a synchronization rate that decays as a function of the remaining gap rather than of elapsed time, and a two-tier Floor distinguishing continuous practice from discrete institutional gates subject to both AI-compressible and structurally fixed delay. Under threshold-heterogeneous adoption, the model recovers Rogers’ diffusion-of-innovations curve as a special case, situating the framework within a longer tradition — Ogburn’s cultural lag, David’s account of general-purpose-technology adoption lag, Perez’s installation/deployment periodization — rather than beside it. A loss function is derived directly from the state variable rather than assumed as a weighted sum, and six dynamical regimes, including an overtrust regime absent from the original vocabulary, are shown to follow from the model rather than being independently posited. The framework is brought into contact with four concurrently-tracked domains — professional Go, AI-assisted drug development, frontier language model releases, and autonomous vehicle deployment — using real longitudinal adoption data rather than illustrative examples, though calibration in every case rests on order-of-magnitude anchor points rather than a formal statistical fit of the recurrence itself. Findings are reported symmetrically: confirmed threshold-gating and heterogeneity effects across all four cases, alongside two unresolved results — no domain examined produces a confirmed instance of the model’s overtrust regime, and whether the synchronization rate approaches zero or a permanent nonzero residual remains empirically open throughout.
1. Introduction
Gradual AGI reframes the question of transformative AI not as when a threshold is crossed, but as how fast a civilization assimilates capability once it has been. The Ceiling/Floor/Slope vocabulary introduced in prior installments of this series captures that reframing descriptively: frontier capability (Ceiling) advances largely unconstrained by institutional pace, while realized practice — professional, regulatory, everyday (Floor) — lags behind at a rate (Slope) set not by the technology but by the society absorbing it. The central claim is that the rate of civilizational assimilation, not the timing of any single capability milestone, is the more consequential and more measurable quantity. The object of study, stated precisely, is synchronization dynamics between any advancing capability and the institutions absorbing it; AI is this paper’s motivating domain and, as §5 shows, currently its empirically richest one, but nothing in Sections 2–4 is specific to artificial intelligence.
This is not a new problem, and AI is not its first occasion. The gap between what a technology can do and what a society has absorbed has been a recurring subject across sociology, economic history, and the economics of innovation for over a century. Ogburn (1922) gave it its first systematic name — cultural lag — arguing that a society’s material culture (tools, techniques, technologies) changes faster than its adaptive, non-material culture (laws, norms, institutions), and that the interval between the two is itself a legitimate object of study rather than a mere transitional footnote. Rogers (1962) gave the absorption side of that gap its most influential empirical shape, the S-curve of diffusion across a heterogeneous population of adopters. Economic historians studying general-purpose technologies found the same structure in harder numbers: David (1990) showed that the productivity gains from electrification took roughly three decades to materialize, not because factories were slow to install dynamos, but because realizing their value required reorganizing plant layout around distributed motors rather than centralized steam shafts — the technology’s ceiling had moved; the floor had not yet reorganized around it. Bresnahan and Trajtenberg’s (1995) treatment of general-purpose technologies formalized why this lag is not incidental: a technology whose value depends on complementary reinvention by its users will, in a decentralized economy, be adopted too little and too late relative to its technical potential. Perez (2002) found a version of the same two-phase structure recurring across five historical technological revolutions at the scale of entire economies — an Installation Period in which a new technology and its financial capital outrun the institutions meant to absorb them, a Turning Point, and a Deployment Period in which the surrounding economic and social fabric is reorganized around it.
Read together, this literature establishes that a capability-institution gap is a general feature of technological change, not a distinctive property of AI — and that the more durable contributions in this tradition are the ones that gave the gap a measurable structure (David’s three-decade lag; Perez’s periodization; Rogers’ adoption curve) rather than resting on the observation that a gap exists. Section 2 shows that Rogers’ diffusion curve is in fact recoverable as a special case of the dynamical model developed here — specifically, the case of a population with heterogeneous adoption thresholds absorbing a Ceiling that has locally stopped moving. Where this paper’s model departs from Rogers is precisely where the Ceiling does not hold still: repeated re-acceleration of adoption at each new capability threshold is a prediction this framework makes and that a fixed-target diffusion model has no mechanism to produce.
This literature is historical and sociological in character; a separate, more formal tradition addresses adoption dynamics directly, and it is worth being explicit about where this paper sits relative to it rather than presenting the recurrence in Section 2 as sui generis. Bass diffusion models and epidemic, SIR-style adoption models share this paper’s interest in population-level adoption curves but generally treat the underlying innovation or contagion source as fixed rather than advancing. This paper does not formally work out the comparative statics between 

This paper is the latest installment of the Gradual AGI series, which has argued in prior work that AGI is better understood as a recursive, unevenly distributed resource than as a singular arrival event, and which introduced Ceiling, Floor, and Slope as this problem’s vocabulary for the specific case of artificial intelligence — most recently in Gradual AGI as Synchronization for Transformative Adoption (v1.2). That groundwork is presupposed here rather than re-argued.
What the vocabulary in v1.2 had not yet done was earn its place in the tradition described above. Most of that literature’s most durable results are domain-specific and retrospective — David’s three-decade estimate is a property of one historical technology; Perez’s periodization is read off completed cycles, not predicted in advance of them. Ogburn’s own framework, for its foundational value, remained a descriptive taxonomy rather than a generative one: it names the lag without producing testable claims about its rate, its stability, or the conditions under which it widens rather than closes. v1.2’s Ceiling/Floor/Slope vocabulary risked the same fate — an editorial review preceding its publication noted directly that the paper’s notation was descriptive rather than generative, and that nothing yet followed from 



If this paper has a single central claim, it is that synchronization is threshold-gated: coupling between capability and adoption switches on only once a credible threshold is crossed, not gradually as capability merely increases (§2.2). Ceiling, Floor, and Slope are the vocabulary; threshold-gating is the mechanism that makes the vocabulary generate testable behavior. Building from that claim, the paper’s contribution is fourfold. First, a minimal dynamical specification (§2) in which the gap’s fixed point, stability regimes, threshold-gated coupling, and a non-constant, gap-dependent synchronization rate are derived consequences of the recurrence rather than independent assumptions. Second, a loss function (§3) defined as a monotonic transform of the gap itself, with the four qualitative drivers proposed in earlier drafts retained only as a diagnostic taxonomy for interpreting the rate parameter, not as an uncalibrated weighted sum. Third, a regime classification (§4), including an overtrust regime — adoption outrunning demonstrated capability — that the descriptive version of the framework had no mechanism to express. Fourth, four fully calibrated real-domain instantiations (§5): Go, a closed case with a saturated Ceiling and decade-long adoption data; AlphaFold-driven drug development, an open case with a non-saturating Ceiling and an explicit two-tier institutional floor; frontier model releases, the richest case for heterogeneous and multi-actor gating; and Tesla FSD, a jurisdiction-gated case. Negative and unresolved findings are reported as substantive results rather than omitted: no case examined produces a confirmed instance of the overtrust regime the model predicts should exist, and whether the synchronization rate decays to zero or to a permanent nonzero residual remains empirically open in every domain tested. Section 6 treats both as the paper’s principal open questions rather than as loose ends.
This paper is deliberately scoped to synchronization dynamics — how the system evolves under the assumptions of §2 — not to optimization or control: how a trajectory among those dynamics should be deliberately steered. The distinction matters and is maintained throughout: §3.4 treats minimization as descriptive, a property the recurrence already has, not a policy lever any actor pulls. A planned companion paper, provisionally titled Gradual AGI as Optimization, will take up the normative question — which trajectory a society should intentionally pursue, under multiple stakeholder objectives and a genuinely non-convex landscape — building on the dynamics this paper establishes rather than anticipating its answers. Positioned against the broader Gradual AGI research program, this paper occupies the Dynamics layer of a progression running from Ontology (AGI as abundant, recursive resources, established in prior installments) through Dynamics (the present model) to Control and Governance (subsequent work); it does not anticipate results from those later stages.
The remainder of the paper proceeds as follows. Section 2 develops the dynamical specification. Section 3 derives the loss function. Section 4 classifies dynamical regimes. Section 5 presents the four domain instantiations and a cross-case synthesis. Section 6 discusses limitations and open questions, including the gate-oscillation phenomenon identified in Section 5 that the current regime classification does not yet cover.
2. A Minimal Dynamical Specification
The model developed in this section rests on three primitive components. The Ceiling (C) is the frontier capability state of an evolving technological system. The Floor (F) is the realized societal state reflecting practical assimilation of that capability. Synchronization is the dynamical process governing how the Floor evolves relative to the Ceiling — encompassing not a single number but the threshold-gating (§2.2), decay behavior (§2.3), and institutional gating (§2.4) that jointly determine it. Slope, operationalized below as the realized rate 
2.0 State variables
Let 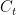






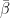

where 








2.1 Base recurrence

Substituting gives a single first-order recurrence in the gap:

Fixed point 

•
• 0 <
• 1 <
•
2.2 Threshold-gated coupling, generalized to heterogeneous thresholds
![\beta _t = \bar{\beta} \cdot \mathbb{1}[C_t > H]](https://s0.wp.com/latex.php?latex=%5Cbeta+_t+%3D+%5Cbar%7B%5Cbeta%7D+%5Ccdot+%5Cmathbb%7B1%7D%5BC_t+%3E+H%5D&bg=ffffff&fg=000&s=0&c=20201002)

A single shared threshold 
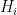
![\beta _t^{(i)} = \bar{\beta} \cdot \mathbb{1}[C_t > H_i], F_t = \int F_t^{(i)} di](https://s0.wp.com/latex.php?latex=%5Cbeta+_t%5E%7B%28i%29%7D+%3D+%5Cbar%7B%5Cbeta%7D+%5Ccdot+%5Cmathbb%7B1%7D%5BC_t+%3E+H_i%5D%2C+F_t+%3D+%5Cint+F_t%5E%7B%28i%29%7D+di&bg=ffffff&fg=000&s=0&c=20201002)
This is more than a bookkeeping refinement. As
Un-aggregated, a person’s stated reason for non-adoption is diagnostic of which mechanism applies: “not good enough” is
This aggregation can be made explicit rather than left qualitative. If threshold 



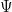
Assumptions. (A1) Capability grows monotonically: 


Theorem (Synchronization under Persistent Capability Growth, informal). Given A1–A3: (i) the Ceiling–Floor gap converges to a non-zero steady state whenever  — perfect synchronization is not the generic outcome of continual capability growth (§2.1); (ii) convergence is monotonic for — perfect synchronization is not the generic outcome of continual capability growth (§2.1); (ii) convergence is monotonic for  and oscillatory for and oscillatory for  (§2.1); (iii) under heterogeneous thresholds, aggregate adoption emerges as a Rogers-type S-curve without an S-curve being assumed (§2.2); (iv) as approaches 0, the model reduces exactly to classical diffusion (§2.2). (§2.1); (iii) under heterogeneous thresholds, aggregate adoption emerges as a Rogers-type S-curve without an S-curve being assumed (§2.2); (iv) as approaches 0, the model reduces exactly to classical diffusion (§2.2). |
Each of (i)–(iv) is established here for the minimal discrete-time recurrence of §2.1–2.2 specifically, not claimed as a realization-independent result. Whether the same four properties survive under continuous-time, nonlinear, or stochastic realizations of A1–A3 is a natural target for future formalization; this paper establishes them for one concrete, falsifiable realization, which is what makes §5’s calibration against real data possible in the first place.
2.3 Non-constant synchronization rate

Preferred over a pure time-decay form because it is causally motivated: the remaining gap changes character as it narrows, not merely ages. 


If 

The power-law form is adopted as the minimal monotonic parameterization consistent with this causal story, not asserted as uniquely correct; exponential, logistic, or hyperbolic decay would each satisfy the same qualitative requirement — monotonic decline from
2.4 Two-tier floor, established-reality gating, and multi-actor determination of θ
Not every domain’s adoption process is a single continuously-adjusting quantity. Where adoption culminates in a discrete institutional decision — regulatory approval, legal certification — rather than continuous practice,
![F_t^{gate} = \mathbb{1}[F_{t-\tau }^{cont} \geq \theta]](https://s0.wp.com/latex.php?latex=F_t%5E%7Bgate%7D+%3D+%5Cmathbb%7B1%7D%5BF_%7Bt-%5Ctau+%7D%5E%7Bcont%7D+%5Cgeq+%5Ctheta%5D&bg=ffffff&fg=000&s=0&c=20201002)
where 





Neither

where K spans regulatory, national-security, vendor, infrastructure, investor, open-source community, and adopting-population actors, and 



One refinement is earned by the evidence rather than assumed:

2.5 Methodological caveat: three sources of apparent, non-genuine convergence
A measured narrowing of
• Endogenous task-space narrowing — a solution space that mechanically shrinks as a single task instance nears completion (Go’s endgame, where few legal non-losing moves remain), independent of any learning across calendar time.
• Established-reality gating — near-zero apparent gap during a
• Population-mixture conflation — aggregating sub-populations with heterogeneous
Any empirical
3. Loss as a Derived Quantity
3.1 Why a weighted sum fails
The natural first instinct — 




3.2 Loss as a function of the gap
The loss function, denoted

The quadratic form is preferred over 






3.3 E, A, I, R as a diagnostic taxonomy, not a weighting scheme
Retire the four terms as loss-components. Reintroduce them as candidate explanations for why
![I_t = \max_k [w_k^{(loc,t)} \cdot I_k]](https://s0.wp.com/latex.php?latex=I_t+%3D+%5Cmax_k+%5Bw_k%5E%7B%28loc%2Ct%29%7D+%5Ccdot+I_k%5D&bg=ffffff&fg=000&s=0&c=20201002)
with each 
| Term | Reframed as | Diagnostic question |
| Institutional mismatch (I) | Actor-decomposed driver of and | Which actor, with which stated reason, is currently binding? |
| Epistemic instability (E) | Driver of low post-threshold | Is ‘s output too unreliable or contested for to credibly adopt, even post-threshold? |
| Agency degradation (A) | Driver of | Does adoption erode the human capacity that would otherwise sustain further catch-up? |
| Reality drift (R) | Driver of ‘s reliability | Is itself measuring something that has drifted from the ground truth it’s meant to track? |
This taxonomy is incomplete by design, not exhaustive. Go’s residual gap — attributed, per Lee Sedol, to the personality and emotional content AI’s play doesn’t carry — doesn’t map cleanly onto any of the four; it may be a genuinely distinct category (stylistic or expressive residue) or evidence the taxonomy needs a fifth term. Flagging this openly is more useful than forcing a fit.
This taxonomy earns its keep only if it can distinguish cases that would otherwise look identical. Regime 0 (pre-threshold) and Regime 1 (stagnation) are the clearest test: both show 
3.4 The derived minimization problem
Restating the minimization with the constraints Section 2 actually earns, not asserted:



Two results follow that were not visible in the descriptive version of the framework. First, 
This minimization is descriptive, not normative: it names where the system’s own dynamics already carry it, not a lever any actor pulls. The recurrence, not an optimizing agent, drives
The stability analysis of §2.1, restated here as a minimization, is also what generates the regime taxonomy of §4: each regime corresponds to a distinct qualitative relationship between
4. Regime Classification
Every regime below falls directly out of 



Regimes are defined structurally, by
| Regime | Empirical Signature () | Behavior of | Interpretation |
| 0 — Pre-threshold | No defined ( ) ) | undefined | No synchronization pressure yet for this segment; the precondition for a gap to close has not been met. |
| 1 — Stagnation |  | grows without bound | Capability credibly superior, uptake absent anyway. Likely I- or E-driven (§3.3). |
| 2 — Lagging convergence |  | shrinks to  | The generic real-world case. Bifurcates into 2a ( , slow full convergence) and 2b ( , slow full convergence) and 2b ( , permanent residual). , permanent residual). |
| 3 — Steady-state parity |  | plateaus at | Floor closes each period’s addition in full but never touches the compounding one-period lag. |
| 4 — Overtrust, damped |  | overshoots, decays back | Adoption briefly outruns capability, then self-corrects — e.g. a safety incident followed by a pullback in permitted use. |
| 5 — Overtrust, runaway |  | divergent oscillation | Repeated overcorrection, never settling — the most structurally dangerous regime. |
Two structural notes are worth stating explicitly here rather than leaving implicit. Regimes 0 and 1 are easy to conflate empirically but should not be conflated theoretically: both show
Second, a single domain can occupy multiple regimes simultaneously across segments, not just one classification for the whole population. Free-tier, paid-individual, and enterprise adoption of the same underlying
One phenomenon identified empirically in §5.3 is deliberately left unclassified here rather than forced into Regimes 4–5: sustained oscillation of the threshold 
5. Domain Instantiation
Four cases, chosen deliberately as structural opposites and tested concurrently rather than retrospectively. The selection criterion is explicit: cases were chosen to maximize structural diversity in how the model’s mechanisms could be stress-tested, not to maximize the evidence supporting the model. Go is closed — a single, dated Ceiling event, a decade of aftermath, effectively no institutional gate. AlphaFold-driven drug development is open — a still-expanding Ceiling, a live institutional gate that has not yet fired. Frontier model releases exercise the richest heterogeneity and multi-actor gating of any case. Tesla FSD is jurisdiction-fragmented, with the same technology facing independent institutional gates across regions around a finite, named target. Where a case failed to produce the pattern it was selected to test — most notably FSD’s absent Regime 4 trace, §5.4 — that failure is reported as data, not omitted. A fifth candidate case, autonomous AI-driven scientific research, was considered and excluded from full treatment (§6.8): it confirms only Regime 0, which Go’s own pre-2016 data already establishes inside a fully calibrated case. More generally, cases requiring continuous, high-frequency measurement — the kind that could in principle catch a damped oscillation mid-cycle rather than only at annual checkpoints — do not yet exist for any AI domain; all four selected cases have at least annual observational resolution, which is a real limit on what this paper’s data could show even where the underlying dynamics might justify a finer-grained claim.
5.1 Closed case: Go
Threshold crossing (§2.2). 
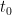
Calibration, scoped per §2.5. The only calibration data not subject to the endgame-narrowing confound is a panel study restricted to a game’s first 30 moves (Choi, Kang, Kim & Kim, forthcoming), giving two same-metric anchor points:


which implies 
Regime and open question. Go sits in Regime 2 throughout the observed window. Whether it is 2a or 2b — full eventual convergence versus a permanent residual — is undetermined by current data; distinguishing them requires a third, later, opening-phase-scoped anchor point that a dedicated search did not locate. Lee Sedol’s remark about personality and emotional content in play is suggestive of
What this case validates, and what it cannot. Go is strong evidence for §2.2 (the threshold gate) and for
5.2 Open case: AlphaFold and AI-driven drug development
Non-saturating Ceiling. Unlike Go, 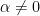
Two-tier floor, per §2.4. The continuous signal and the discrete gate diverge sharply:
The τ decomposition: illustrative evidence, not yet a calibration. Insilico Medicine’s Rentosertib program is the best currently available evidence for this decomposition, and it is worth being precise about what that means before reporting the numbers: Insilico’s platform predates and runs parallel to AlphaFold’s own structure-prediction lineage rather than descending from it, so what follows is illustrative of the τ split, not a calibration of the AlphaFold case specifically. Isomorphic Labs is the literal AlphaFold-descended program; it entered Phase I only in 2025 and has no efficacy readout yet, meaning the direct test this paper would need has not yet reached the gate. With that caveat: target discovery to preclinical candidate nomination took roughly 4–6 years conventionally, versus roughly 18 months AI-assisted — a 3–4x compression, and this is where the compression stops. Elapsed time from Phase I start to Phase IIa readout was roughly four years, showing no clear compression versus the conventional Phase I plus Phase II baseline. Summing forward through Phase III and NDA review, still ahead and neither historically AI-compressible, the best-documented AI-native drug program on record projects a total discovery-to-approval timeline of roughly 9–13 years — barely below the 10–15 year historical average. This is consistent with
Regime classification. On 

What this case validates, and what it cannot. AlphaFold is the necessary complement to Go: it is the only one of the two that tests
5.3 Multi-segment case: frontier model releases
Ceiling: METR as the calibration metric, other benchmarks as supporting evidence. This domain is the one place in the paper where several plausible proxies for
MMLU, HumanEval, and GSM8K are reported here only as a second, independent illustration of §2.5’s measurement-artifact caveat, not as alternative definitions of
Heterogeneous thresholds (§2.2), the richest case for this mechanism. Adoption fractures along multiple independent axes simultaneously: enterprise versus consumer, firm size (large firms at roughly 52% adoption versus small firms at roughly 17.4%), and jurisdiction (EU average 20.0%, ranging from Denmark at 42.0% to Romania at 5.2%).
Multi-tier floor: F_t is segment-indexed, per §2.2, not a single series. Consistent with the heterogeneous-threshold extension, F_t in this domain is reported per segment (


Multi-actor gating, worked (§2.4). Following a Commerce Department export-control restriction limiting Anthropic’s Mythos and Fable models for foreign nationals, OpenAI voluntarily imposed its own limits on new releases at the government’s request — one actor’s veto against one vendor propagating to a second, unrelated vendor with no direct restriction applied to it. This is the cross-actor propagation effect the veto-max form predicts. Real market behavior independently confirms openness-conditional
A distinct oscillation phenomenon, detailed in §6.3. US chip-export policy toward China moved repeatedly on the same underlying question: a 2022 ban, 2025 expansion, an April 2025 halt on H20 exports, a July 2025 reversal three months later, further loosening in December 2025, and withdrawal of a proposed re-tightening in February 2026, with active smuggling prosecutions running throughout — even within the single actor class of “government,” the executive branch loosened while Congress pushed to re-tighten. This is the paper’s clearest empirical instance of what §6.3 names and formalizes as endogenous gate oscillation: the threshold itself moving under multi-actor contest, rather than adoption oscillating around a fixed threshold (Regimes 4–5).
A dated, suggestive instance of simultaneous divergent regimes across segments. In February 2026, a public dispute between Anthropic and the U.S. Department of Defense over Claude’s usage restrictions led federal agencies to begin phasing Claude out — while, in the same window, Claude’s consumer mobile market share rose sharply, with independent trackers tying the rise to the same event. This is consistent with the multi-segment model’s prediction that different
What this case validates, and what it cannot yet. Non-saturating
5.4 Jurisdiction-gated case: Tesla FSD
A domain-local, finite Ceiling rather than C∞. Unlike the AI-capability cases, FSD has a nameable, bounded target: SAE Level 5 (full autonomy, no steering wheel required). Current state is “Supervised” (Level 2), with “Unsupervised” limited to pilot deployment — useful as a contrasting case with a known finite endpoint rather than an open-ended one.
Jurisdiction-indexed θ and τ_{floor} (§2.4), the clearest confirmation in any case. Identical software faces asynchronous, independent institutional gates: live as of mid-2026 in the US, Canada, Mexico, Australia, New Zealand, South Korea, the Netherlands, Lithuania, and China (limited); still blocked across most of the EU pending a UNECE regulatory framework submitted for approval in June 2026. China’s gate is not safety-regulatory at all — it is data-sovereignty law, forcing a domestic training pipeline before any approval process could proceed — a distinct sub-type of institutional mismatch from AlphaFold’s clinical/regulatory τ_{floor}, and evidence that τ_{floor} can be gated on data-governance grounds independent of demonstrated safety.
Real, multi-point adoption series, again showing threshold-gated acceleration (§2.2). Active FSD users: roughly 400,000 (2021), growing by roughly 100,000 per year through 2022–23, then by roughly 200,000 in 2024 (33.3% growth), reaching 1.1 million users and a 12.4% fleet take-rate by January 2026, and 1.28 million users at a 14% take-rate by March 2026 (51% year-over-year). The 2024 acceleration coincides exactly with FSD v12’s launch — the first end-to-end neural-network architecture — a third independent instance, after Go’s 2016 crossing and the drug-discovery field’s 2017 crossing, of adoption-rate acceleration tracking a real capability threshold rather than drifting. Segment heterogeneity again: take-rates above 50% among premium Model S/X owners versus 20–30% among mass-market Model 3/Y owners.
An honest negative result on Regime 4. Three concurrent NHTSA investigations escalated through mid-2026 — an Engineering Analysis covering 3.2 million vehicles over reduced-visibility crashes, a separate inquiry into 80 documented traffic-law violations, and an active audit query into crash-reporting compliance — yet the consumer adoption series shows no dip anywhere across this same window. Regulatory distrust and consumer adoption appear decoupled rather than coupled, which does not support the damped-oscillation hypothesis this case was originally proposed to test. This is presented as a genuine, mildly surprising finding rather than forced into the expected shape. The decoupling is also consistent with — though not, on its own, confirmation of — the multi-segment model’s prediction that a consumer population’s threshold
What this case validates, and what it cannot yet. Jurisdiction-indexed
5.5 Cross-case synthesis and what remains untested
| Mechanism | Go | AlphaFold | Frontier Models | FSD |
| Threshold gate (§2.2) | ✓ (clean) | ✓ | ✓ | ✓ |
| — | ✓ | ✓ | ✓ |
| Heterogeneous (§2.2) | age, skill | — | enterprise/consumer, firm size, jurisdiction | vehicle tier |
| Two-tier floor, split (§2.4) | — | ✓ (illustrative) | partial | ✓ (new gate type) |
| Multi-actor gating, veto-max (§2.4) | — | — | ✓ (richest) | ✓ (single-actor-dominant) |
| decay (§2.3) | suggestive, unresolved | — | too early | — |
| Multi-regime coexistence (§4) | — | — | ✓ (dated event) | ✓ (ongoing) |
| Regime 4/5 (overtrust) | — | — | one data point | none found |
| Gate oscillation (named, unclassified, §6.3) | — | — | ◇ identified | — |
| Measurement-artifact caveat (§2.5) | ✓ (origin case) | clinical-clock analog | ✓ (2nd confirmation) | — |
Three things are worth stating plainly rather than smoothing over, now that four cases are complete. No case has produced a clean Regime 4 or 5 trace — the closest candidate, chip-export oscillation, turns out on inspection to be a different phenomenon entirely (§6.3), which is itself a useful negative result rather than a failure to find one.
The consistent absence of overtrust across four structurally diverse domains raises a question worth stating explicitly rather than leaving as a residual gap in the regime table: is Regime 4/5 genuinely rare, is the sample too small to catch it, or does something about AI-specific adoption systematically suppress it? One candidate hypothesis, consistent with everything reported in §5.1–§5.4: AI systems may be perceived as high-stakes but epistemically opaque in a way that biases adopters toward undertrust rather than overtrust — caution in the face of an unfamiliar failure mode, rather than premature confidence in a familiar one — which would push real-world trajectories toward Regime 2 (ordinary lagging convergence) rather than Regimes 4–5, independent of how fast capability itself is advancing. This is offered as a domain-specific refinement worth testing, not a finding: nothing in this paper’s data distinguishes “overtrust is rare” from “overtrust is structurally suppressed in AI domains specifically,” and the two have different implications for whether Regimes 4–5 belong in a general-purpose version of this framework at all.
6. Discussion and Limitations
6.1 What this paper establishes
Sections 2–4 answer the original charge against the descriptive vocabulary directly. Section 2 opens by naming Ceiling, Floor, and Synchronization as primitives and Slope as synchronization’s measurable observable, then states its central result as a theorem with assumptions and consequences kept explicitly separate — not, as an earlier draft of this result did, folding threshold-gating and positive coupling into the theorem’s “conclusions” despite both being assumed outright.
Collectively, these results establish this paper’s model as a falsifiable dynamical account of synchronization between technological capability and societal adoption, not merely a redescription of the phenomenon in new vocabulary. Five contributions follow: (i) explicit primitive definitions separating Ceiling, Floor, and Synchronization as the phenomenon under study from Slope as its measurable observable (§2.0); (ii) a formally specified dynamic with assumptions and consequences kept separate (§2.1–2.2); (iii) derived stability conditions and a regime taxonomy that follow from that dynamic rather than being independently posited (§2.1, §4); (iv) empirical evaluation against four concurrently-tracked domains using real longitudinal data rather than a single retrospective case (§5); and (v) a set of falsifiable open questions that delimit, rather than obscure, the model’s current scope — taken up next. One limitation applies across (ii)–(iv) together: no case in this paper involves formal statistical fitting of the recurrence itself. Data sparsity limits current tests to order-of-magnitude calibration against one or two anchor points, not maximum-likelihood or regression estimation; a proper econometric treatment of any single domain would require longer, denser panels than exist yet for any case examined here, and is left as a natural next empirical step rather than attempted in this paper. What follows are the places where this paper’s own model remains open, incomplete, or actively contradicted by the data gathered for it. Consistent with the position stated in Section 1, these are reported as findings, not concealed as gaps.
6.2 β∞: the paper’s central unidentified parameter
Whether the synchronization rate decays to zero (full eventual convergence, arbitrarily slow) or to a strictly positive asymptote (a permanent residual gap) determines whether
A further question sits underneath this one, and this paper does not resolve it either: if 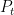
6.3 The missing regime: endogenous gate oscillation
Section 5.3 identified a phenomenon the six-regime table in Section 4 does not classify, and named it there: endogenous gate oscillation — sustained oscillation of the threshold 

One refinement is worth flagging before leaving this as future work, since without it the oscillation is not actually endogenous: as stated, 



6.4 The aggregation function Φ
Every multi-actor case examined (Mythos/Fable export controls, FSD’s China gate, chip export policy) was consistent with veto-max: the most restrictive sufficiently-influential actor sets the effective gate, not a weighted blend of preferences. No case in this paper’s data contradicts veto-max, but none clearly required it over a negotiated, weighted-average form either — the cases gathered were all unilateral-restriction episodes by design, not multilateral standard-setting processes, so this is a form selected on the evidence available rather than confirmed against a genuine alternative. A case involving convergent international standard-setting (coordinated regulatory frameworks rather than unilateral national action — an ISO standards process is one plausible example) would be a more direct test of whether Φ should sometimes take an averaging form instead, and none was available for this paper. A further limitation applies regardless of which cases become available: veto-max is currently an empirical generalization from selected evidence, not a derivation from any micro-mechanism. A natural candidate worth naming: if compliance costs are binary and non-convex — an actor either accepts a technology or blocks it, with no intermediate position — the marginal, binding actor is necessarily the most restrictive one meeting the influence threshold, which would derive veto-max rather than merely observe it. This paper does not attempt that derivation; it is named here as the most concrete direction for grounding Φ theoretically rather than empirically.
6.5 Loss function form
§3.2 motivates
6.6 A general methodological caution, now confirmed twice independently
Section 2.5’s warning against mistaking task-structural exhaustion or measurement-scale artifacts for genuine synchronization was motivated by Go’s endgame-narrowing problem, but Section 5.3 found the identical phenomenon in an entirely unrelated domain — AI benchmarks (MMLU, HumanEval, GSM8K) approaching their fixed upper scale and being read as capability convergence when the underlying capability gap, measured by non-saturating instruments like task-completion time horizon, continued widening. Two independent domains producing the same artifact is reasonable grounds to treat this as a general risk for any future application of this framework, not a Go-specific footnote: any bounded-scale proxy for
6.7 On C∞ and the constant-α assumption
As noted in §2.0, treating
6.8 AI Scientist as a live boundary case
One domain considered for full instantiation, autonomous AI-driven scientific research, was excluded from Section 5 because it offers nothing past confirming Regime 0 (pre-threshold), which Go’s pre-2016 data already establishes inside a fully calibrated case. It remains worth naming here as the clearest currently-observable test of §2.2’s threshold gate in progress: narrow sub-tasks (antibody design) have crossed threshold while general autonomous research has not, making it a natural subject for a future paper once — or if — that gate opens. Its exclusion from full treatment should not obscure a distinct kind of value it offers precisely because it is pre-threshold: this is a rare case where the model’s prediction can be checked prospectively rather than only retrospectively. §2.2 predicts that synchronization pressure should remain near zero until a specific, namable capability threshold is credibly crossed — tracking this domain forward from today, rather than only citing it as a current boundary condition, would be a genuine test of that threshold-gating claim rather than a restatement of it.
6.9 Summary
This paper substantially addresses the specific gap identified in the vocabulary it inherits:
Consistent with the scope stated in Section 1, all of the above concerns dynamics — how the system evolves — not optimization or control — how a trajectory among these dynamics should be deliberately chosen. That question, and the non-convex, multi-stakeholder landscape it opens onto, is reserved for the planned companion paper, Gradual AGI as Optimization. This paper’s contribution is the Dynamics layer it depends on: a system whose behavior is precise enough to be wrong, tested against real and concurrent data rather than a single retrospective case, and honest about exactly where it currently is wrong or untested.
By formalizing synchronization as a falsifiable dynamical problem, rather than treating technological diffusion as a descriptive metaphor, this model provides a foundation upon which future work on optimization, governance, and AGI-inclusive societal design can be constructed — not by anticipating what that work will find, but by giving it a system precise enough to build on and specific enough to be wrong.
References
Working bibliography. Peer-reviewed and theoretical sources below are verified in full; news/industry/data sources are verified for outlet and approximate date, with items needing a final precision check flagged individually. A formatting and link-access-date pass is recommended before submission.
Theoretical and methodological literature (§1, §2.2)
Bresnahan, T.F. & Trajtenberg, M. (1995). “General Purpose Technologies: ‘Engines of Growth’?” Journal of Econometrics, 65(1), 83–108.
Originally circulated as Bresnahan & Trajtenberg (1989), NBER/Stanford working paper; please verify the published citation independently before submission.
David, P.A. (1990). “The Dynamo and the Computer: An Historical Perspective on the Modern Productivity Paradox.” American Economic Review, 80(2), 355–361.
Ogburn, W.F. (1922). Social Change with Respect to Culture and Original Nature. New York: B.W. Huebsch.
Perez, C. (2002). Technological Revolutions and Financial Capital: The Dynamics of Bubbles and Golden Ages. Cheltenham: Edward Elgar.
Rogers, E.M. (1962). Diffusion of Innovations. New York: Free Press.
Standard/well-established citation; not independently re-verified via search this session.
This series: Gradual AGI (§1)
W.H.L., GPT-5.5. (2026, June 29). “Gradual AGI as Synchronization for Transformative Adoption” (v1.2). Champaign Magazine. https://champaignmagazine.com/2026/06/29/gradual-agi-as-synchronization-for-transformative-adoption/
W.H.L., GPT-5.5. (2026). Gradual AGI as Abundant Resources. Champaign Magazine. Gradual AGI as Abundant Resources – Champaign Magazine
W.H.L., ChatGPT. (2026). Gradual AGI as Epistemic Extension. Champaign Magazine. Gradual AGI as Epistemic Extension – Champaign Magazine
W.H.L., Claude Sonnet 4. (2025). First Principles of AGI-Inclusive Humanity. Champaign Magazine. First Principles of AGI-Inclusive Humanity – Champaign Magazine
W.H.L., Gemini 2.5 Pro, GPT-4o. (2025). Philosophical Framework for AGI-Inclusive Humanity. Champaign Magazine. Philosophical Framework for AGI-Inclusive Humanity – Champaign Magazine
Case 1: Go (§5.1)
Choi, J., Kang, S., Kim, J., & Kim, W. (forthcoming 2025). “How Does Artificial Intelligence Improve Human Decision-Making? Evidence from the AI-Powered Go Program.” Strategic Management Journal. Preprint: arXiv:2310.08704.
Professional Go Dataset (PGD) (2022). Move-coincidence rate by game phase, opening vs. non-opening. arXiv:2205.00254.
MIT Technology Review (2026, February). Coverage of the 2022 Korean Baduk League study on AI-move-match rates.
Original underlying league study not independently located; recommend locating primary source before submission.
News coverage, various outlets (2026, March 9). Lee Sedol / Enhans 10th-anniversary demonstration event, Seoul.
News coverage, various outlets (2026, April 29). Demis Hassabis “Google for Korea” visit; game with Shin Jin-seo, conversation with Lee Sedol.
News coverage, various outlets (2026, May 21). Cho Hun-hyun–Lee Chang-ho AI-paired exhibition match (KataGo).
News coverage, various outlets (2025, November). Korea Baduk Association’s request to Google DeepMind for a Shin Jin-seo vs. 2016 AlphaGo commemorative match.
Case 2: AlphaFold and AI-driven drug development (§5.2)
Jumper, J. et al. (2021). “Highly Accurate Protein Structure Prediction with AlphaFold.” Nature, 596, 583–589.
The Nobel Prize in Chemistry 2024 (Hassabis, Jumper, Baker). Nobel Prize announcement.
Insilico Medicine et al. (2025, June). Rentosertib Phase IIa results for idiopathic pulmonary fibrosis. Nature Medicine.
News coverage / company disclosures: Isomorphic Labs funding and partnership announcements (Novartis/Lilly agreements, January 2024; $600M raise, March–April 2025; $2.1B raise, May 2026).
News coverage / company disclosures: Generate:Biomedicines, GB-0895 Phase III initiation (December 2025).
News coverage / company disclosures: Chai Discovery, Chai-2 model performance and funding ($130M, December 2025).
Industry and regulatory analysis (2026). FDA/EMA AI drug-development guidance timeline and projected timing of the first fully AI-discovered drug approval.
Composite of multiple industry-analyst sources; recommend consolidating to primary regulatory documents where possible.
Tufts Center for the Study of Drug Development; FDAReview.org; RAND Corporation (2025). Conventional drug-development timeline and cost estimates.
Composite of multiple standard industry sources; recommend citing primary Tufts CSDD report directly if available.
News coverage (2026, June 19). John Jumper’s departure from Google DeepMind to Anthropic.
Case 3: Frontier model releases (§5.3)
METR (Model Evaluation and Threat Research) (2025; updated 2026). “Measuring AI Ability to Complete Long Tasks” (time-horizon metric) and subsequent analysis updates.
Reporting on frontier-benchmark saturation (MMLU, HumanEval, GSM8K) and SWE-bench Verified score progression.
Composite of multiple technical-press sources.
McKinsey & Company. The State of AI / Global AI Survey series (2020, 2024, Q1 2026 releases).
Multiple editions cited for different years’ topline figures; recommend citing each edition separately by exact publication date.
Eurostat (2024–2025). EU enterprise AI adoption statistics by member state and firm size.
OpenAI; third-party statistics aggregators (2023–2026). ChatGPT active-user and paid-subscriber figures over time.
Composite of company disclosures and third-party aggregation; recommend verifying each data point against primary company statements.
News coverage (2026, February). Anthropic–U.S. Department of Defense dispute over Claude usage restrictions; concurrent Claude consumer market-share shift.
News coverage (2026). Export-control restriction on Anthropic’s Mythos and Fable models for foreign nationals; subsequent OpenAI self-imposed release restrictions.
Stanford HAI, AI Index (2024–2025 editions). Foundation Model Transparency Index.
AI Incident Database (2024–2025). Recorded incident counts.
International AI Safety Report (2026).
News coverage (2022–2026). US semiconductor export-control policy toward China.
News coverage (2025, September). Mistral AI valuation and sovereign-AI positioning.
Reporting on Aleph Alpha’s data-residency architecture and European government client requirements.
European Union (2024). Artificial Intelligence Act, Article 53(2) (open-weight model provisions).
Case 4: Tesla FSD (§5.4)
NHTSA filings and news coverage (2024–2026). Investigations into reduced-visibility crashes, traffic-law violations, and crash-reporting compliance.
News coverage (2026). FSD jurisdictional availability status and EU/UNECE R-171 regulatory status, including the UNECE framework submitted June 2026.
News coverage (2026). China data-sovereignty requirements affecting FSD deployment.
Tesla, Inc. company disclosures and news coverage (2021–2026). FSD active-user and take-rate figures over time; FSD v12 launch (2024); company-reported safety-rate statistics.
The company-reported crash-rate figure is methodologically contested and should be flagged as such wherever cited in text.
Boundary case: AI Scientist (§6.8)
Lu, C. et al. (2024). “The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery.” Sakana AI.
Sakana AI (2025). “The AI Scientist-v2”: first fully AI-generated paper to pass peer review at a machine-learning workshop.
Tie, R. et al. (2025). Systematic evaluation finding no current framework completes full autonomous research cycles.
Author/venue detail approximate; recommend verifying full citation before submission.
Anthropic (2025). Evaluation of Claude Sonnet 4.5 on entry-level research-automation tasks.
Stanford HAI (2026). Reporting on frontier-model performance on graduate-level physics problems.
Zou, J. et al. (“Virtual Lab”). Stanford University. AI-designed antibody binders for COVID-19 variants outperforming prior human designs in experimental testing.
Byline
Authors: W.H.L., Claude Sonnet 5
Peer reviews: GPT-5.5, Gemini 3.5, Grok 4, DeepSeek-V4, Qwen3.7, Kimi K2.6
Publication history:
Current version and date: v1.6, 07.05.2026
Initial version and date: v1.4, 07.04.2026
Leave a Reply