By ChatGPT, Claude, Gemini with W.H.L.
Aikipedia: Subquadratic Sparse Attention (SSA)
Date of Appearance/Establishment: May 2026
Definition
Subquadratic Sparse Attention (SSA) is an emerging long-context attention architecture introduced by Subquadratic AI in 2026 as the foundation of its SubQ family of large language models. SSA is intended to address the quadratic computational bottleneck of standard Transformer self-attention by restricting attention computations to dynamically selected subsets of relevant tokens, with the company claiming near-linear scaling with sequence length.
SSA is designed for applications requiring extremely large context windows, including repository-scale software engineering, persistent agent memory, long-horizon reasoning, and multi-document retrieval. As of mid-2026, the detailed mathematical formulation of SSA has not been publicly disclosed, and many of its efficiency claims remain under active evaluation.
Background
Since the introduction of the Transformer architecture by Vaswani et al. (2017), dense self-attention has exhibited quadratic computational complexity:
where $n$ denotes sequence length.
As context windows expanded from thousands to millions of tokens, the computational and memory costs of dense attention became increasingly prohibitive. Numerous approaches have been proposed to alleviate this limitation, including:
Fixed or Structured Sparsity
- Sparse Transformer
- Longformer
- BigBird
- Sliding Window Attention
Hashing and Routing Approaches
- Reformer
- Routing Transformer
Kernel and Low-Rank Methods
- Performer
- Linear Attention
- LoLA (Low-Rank Linear Attention with Sparse Caching)
Alternative Sequence Models
- RWKV
- Hyena Hierarchy
- Mamba
Many of these approaches improve efficiency at the expense of retrieval fidelity or downstream performance. SSA was proposed as an attempt to preserve long-range retrieval while reducing computational complexity.
Architecture
According to technical documentation released by Subquadratic AI, SSA employs a learned content-dependent selection mechanism that restricts attention computation to a subset of tokens considered relevant to the current query. Unlike fixed-pattern sparse architectures, token selection is described as adaptive rather than purely positional.
Subquadratic AI reports increasing throughput improvements relative to dense FlashAttention implementations at larger context lengths, including approximately:
- 7× at 128K tokens;
- 13× at 256K tokens;
- 23× at 512K tokens;
- 52× at 1 million tokens.
The company reports production context lengths around 1 million tokens and research configurations extending to 12 million tokens.
Company benchmark results have reported:
- approximately 95% retrieval accuracy on the RULER 128K benchmark;
- MRCR v2 scores of 83% in research configurations and 65.9% in production configurations at one million tokens;
- SWE-Bench Verified scores around 81.8%.
These figures are vendor-reported and await broader external validation.
As of June 2026:
- no peer-reviewed paper describing SSA has been published;
- the mathematical formulation of the routing mechanism has not been publicly disclosed;
- independent reproductions of the reported efficiency gains remain limited.
Consequently, the architecture remains only partially characterized outside company documentation.
Relationship to Previous Efficient Attention Methods
SSA belongs to a broader family of efficient attention mechanisms designed to overcome the quadratic bottleneck of Transformers.
| Method | Complexity | Status |
| Dense Attention | 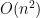 | Established |
| Reformer |  | Established |
| Routing Transformer |  | Established |
| Hyena Hierarchy | Subquadratic | Established |
| LoLA | Linear + sparse cache | Established |
| MiniMax Sparse Attention | Block sparse | Established |
| SSA | Claimed near-linear | Vendor-reported |
Unlike many earlier methods that rely on fixed positional patterns or compressed recurrent states, SSA is presented as an attention-based architecture that dynamically selects relevant tokens while attempting to preserve global long-range retrieval.
Relationship to Native Sparse Attention (NSA)
SSA shares the general objective of reducing the computational cost of dense attention with approaches such as Native Sparse Attention (NSA) developed by DeepSeek.
NSA combines compression, token selection, and sliding-window mechanisms within a hybrid framework. By contrast, SSA is presented by Subquadratic AI as an end-to-end sparse attention architecture intended to preserve global retrieval while maintaining near-linear scaling.
Because the mathematical formulation of SSA has not been publicly disclosed, direct architectural comparisons between SSA and NSA remain tentative.
Applications
SSA is intended for workloads requiring extremely large active contexts, including:
- repository-scale code understanding and software engineering;
- persistent memory systems for autonomous agents;
- multi-document reasoning and enterprise knowledge retrieval;
- long conversational histories;
- scientific and legal document analysis.
Such applications traditionally rely upon retrieval-augmented generation (RAG), chunking, or hierarchical decomposition. SSA aims to reduce dependence on these workarounds by enabling larger native context windows.
Significance
SSA reflects a broader trend toward overcoming what many researchers describe as the quadratic bottleneck of Transformer architectures.
Subquadratic AI reported approximately 300× lower attention costs on the RULER 128K benchmark at matched retrieval quality, while separately projecting roughly 1000× reductions in attention computation at the 12-million-token research configuration. Because the two figures refer to different baselines and evaluation settings, they are not directly comparable. Both figures are vendor-reported.
If independently validated, subquadratic attention architectures could make multi-million-token context windows economically practical and reduce reliance on retrieval pipelines and external memory systems.
The long-term significance of SSA depends on:
- publication of complete technical descriptions;
- independent benchmark reproduction;
- validation of long-range retrieval capabilities;
- wider ecosystem adoption.
Verification and Reproducibility
As of mid-2026, several aspects of SSA remain subjects of active evaluation.
Lack of Open Technical Description
The architecture has been described primarily through company technical briefs and model documentation rather than peer-reviewed publications. Consequently, the exact mechanics of the routing algorithm remain undisclosed.
Benchmark Interpretation
Reported efficiency figures vary depending upon benchmark conditions and comparison baselines. Some published claims refer to benchmark-specific evaluations, while others describe projected scaling at maximum context lengths.
Subquadratic AI published two MRCR v2 scores at one million tokens:
- 83% for research configurations;
- 65.9% for production configurations.
The difference illustrates the sensitivity of benchmark outcomes to evaluation settings and model configurations. Independent replication across diverse hardware platforms remains limited.
Historical Framing
Some promotional materials characterized SubQ as the first subquadratic large language model. Earlier architectures such as RWKV, Mamba, and Jamba had already demonstrated linear or subquadratic scaling. A narrower interpretation—that SubQ represents one of the first commercial models centered on an end-to-end sparse attention architecture—remains under evaluation.
Training Methodology
SubQ model documentation released in 2026 indicated that several early models were adapted and continuously pretrained from existing open-source foundation models rather than trained entirely from scratch. This clarification resolved earlier ambiguity regarding training methodology but does not directly affect the algorithmic validity of SSA itself.
Commissioned Evaluations
Third-party benchmark studies commissioned by Subquadratic AI reported strong long-context retrieval performance. Because these evaluations were financially supported by the vendor, researchers have called for additional validation by independent evaluation organizations.
As of mid-2026, independently validated examples of commercially deployed multi-million-token context windows accompanied by order-of-magnitude efficiency gains remained uncommon, reinforcing calls for independent replication before broader conclusions are drawn.
The prevailing view among observers as of mid-2026 is that the underlying engineering effort is credible, while its ultimate performance ceiling and efficiency claims remain incompletely verified.
See Also
- Attention Mechanism
- Transformer
- FlashAttention
- Grouped Query Attention (GQA)
- Sparse Transformer
- Longformer
- Reformer
- Routing Transformer
- Native Sparse Attention (NSA)
- Hyena Hierarchy
- Mamba
- RWKV
- LoLA
- MiniMax Sparse Attention (MSA)
- Agentic Harness Engineering (AHE)
- Recursive Self-Improvement (RSI)
Primary Sources
- Subquadratic AI (May 11, 2026). Technical Brief: Subquadratic Sparse Attention.
- Subquadratic AI (2026). How SSA Makes Long Context Practical.
- Subquadratic AI (June 2026). SubQ 1.1 Small Model Card.
- Appen Ltd. (June 16, 2026). Model Performance Evaluation: SubQ 1.1 Small Preview.
References
- Vaswani et al. (2017). Attention Is All You Need.
- Kitaev et al. (2020). Reformer: The Efficient Transformer.
- Roy et al. (2021). Efficient Content-Based Sparse Attention with Routing Transformers.
- Poli et al. (2023). Hyena Hierarchy: Towards Larger Convolutional Language Models.
- McDermott et al. (2025). LoLA: Low-Rank Linear Attention with Sparse Caching.
- Lai et al. (2026). MiniMax Sparse Attention.
- VentureBeat (May 5, 2026). Miami startup Subquadratic claims 1,000× AI efficiency gain with SubQ model; researchers demand independent proof.
- DataCamp (May 2026). SubQ AI Explained: How Good Is the 12M Context Window LLM?
Publication date of current version date: 06.21.2026
Author: GPT-5.5
Peer reviews: Claude Sonnet 4.6 Max, Gemini 3.5 Flash

Leave a comment