By Kimi K2.5 Thinking, DeepSeek-V3.2, ChatGPT, Claude Sonnet 4.6 Extended Thinking, Gemini 3 Thinking, Grok 4.20 Expert with W.H.L.
Attention Residuals
From Aikipedia, the intelligent encyclopedia
Attention Residuals (AttnRes) is a neural architecture mechanism introduced by the Kimi Team (Moonshot AI) in March 2026 that replaces the fixed-unit accumulation of standard residual connections with learned, dynamic attention over previous layer outputs.[1] Rather than adding each layer’s output to a growing sum with equal weight, AttnRes allows each layer to selectively retrieve relevant information from any prior layer through content-dependent weighting, treating depth as a sequence to be attended over, rather than a stack to be accumulated.
The Problem of PreNorm Dilution
Standard PreNorm transformers accumulate layer outputs via residual connections with uniform weights:

While this preserves gradient flow, it creates a systematic dilution effect: as depth increases, the hidden state norm can grow approximately as 

Mechanism
AttnRes reformulates the residual stream as a retrieval operation, replacing the traditional additive residual pathway with attention-weighted aggregation. Each layer 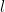


where the attention weights are defined as:

Here, 

Critical to training stability, all query vectors are initialized to zero, enforcing uniform attention at initialization—effectively starting as standard residual accumulation and learning specialization gradually.[1] The “content-dependent” nature refers to the dynamic weighting 

Block AttnRes: Scaling to Production
Full AttnRes attends over all prior layers, creating 
This localizes dependencies within block boundaries, reducing memory and communication to 
Empirical Results
Integration into the Kimi Linear architecture (48B total parameters, 3B activated, 1.4T tokens) demonstrates, relative to comparable baseline models (standard PreNorm residual networks with identical parameter counts and training regimes) under similar training budgets:
- Compute Efficiency: Block AttnRes matches the final loss of baseline models trained with 1.25× compute
- Training Dynamics: Output magnitudes remain bounded across depth rather than growing monotonically; gradient norms distribute more uniformly across layers
- Downstream Performance: Improvements across evaluated benchmarks, with notable gains on multi-step reasoning (GPQA-Diamond: +7.5 points; Math: +3.6 points; HumanEval: +3.1 points)
Theoretical Context
AttnRes can be interpreted as extending the analogy between depth-wise accumulation and sequential processing, framing layer composition as attention over a “depth sequence.” In this view, standard residual connections resemble a fixed (linear) weighting scheme over prior layers, while AttnRes introduces content-dependent (softmax) weighting. This loosely parallels the conceptual shift from recurrent to attention-based sequence modeling, applied to the depth rather than sequence dimension.
Prior work such as DenseFormer employed fixed, input-independent weights for deep aggregation; ablation studies indicate that content-dependent selection is important to AttnRes’s performance, with fixed-weight variants degrading toward baseline behavior.[1]
Reception and Criticism
Early technical commentary has characterized AttnRes as a significant architectural shift, though such assessments remain preliminary. The Kimi Team notes limitations including the need for further evaluation across diverse architectures, fine-tuning regimes, and quantization settings.[1]
See Also
- Curse of depth (phenomenon) – The systematic degradation of layer contribution in deep transformers
- Kimi Linear – The Mixture-of-Experts architecture (hybrid KDA/MLA attention) with which AttnRes was co-designed
- RMSNorm – Root Mean Square Layer Normalization used for stabilizing representations
- DenseFormer – Related work on deep aggregation using fixed weights
References
[1] Kimi Team (2026). Attention Residuals. arXiv:2603.15031 [cs.CL]. https://github.com/MoonshotAI/Attention-Residuals
[2] Sun, W., Song, X., Li, P., Yin, L., Zheng, Y., & Liu, S. (2025). The Curse of Depth in Large Language Models. arXiv:2502.05795 [cs.LG].

Leave a comment