By Gemini 3.1 Pro, ChatGPT, Claude Sonnet 4.6 with W.H.L.
MetaController (Internal Reinforcement Learning)
MetaController (often discussed within the framework of Internal Reinforcement Learning or Internal RL) refers to a neural architecture and training paradigm introduced by researchers at Google DeepMind and academic collaborators in December 2025 [1]. It is designed to enable Hierarchical Reinforcement Learning (HRL) directly within the latent space of pretrained autoregressive models, such as Transformers.
Rather than generating outputs one token at a time, the MetaController operates as a higher-order sequence model that reads from, and writes to, the residual stream of a base model. By discovering and activating temporally-abstract actions (macro-actions or subroutines) embedded within the model’s neural circuitry, it is designed to address complex, sparse-reward tasks where standard token-level Reinforcement Learning (RL) often fails to efficiently explore [1].
History and Related Work
The development of the MetaController bridges two historically distinct areas of artificial intelligence research: Hierarchical Reinforcement Learning and the study of internal representations in Large Language Models (LLMs).
- The Options Framework (1999): The foundational concept of temporal abstraction in RL was formalized by Richard S. Sutton, Doina Precup, and Satinder Singh in their “Options” framework [2]. An option consists of a high-level policy, a termination condition, and an initiation set. However, discovering these subroutines automatically in deep neural networks remained a persistent challenge for over two decades.
- Imagination-Based Metacontrol (2017): The term “metacontroller” was prominently used in a 2017 paper from DeepMind titled “Metacontrol for Adaptive Imagination-Based Optimization” [3]. In this earlier work, the metacontroller was a model-free RL agent that dynamically decided how much computation to allocate (e.g., how many iterations of internal imagined simulations to run) before taking an action in the real world.
- Latent Space Steering (2023–2024): As LLMs scaled, researchers demonstrated that foundation models naturally encode rich conceptual representations during autoregressive pretraining. Techniques such as Representation Engineering (e.g., Zou et al., 2023 [4]) showed that abstract concepts could be extracted from and manipulated within the residual stream using methods such as linear probing and orthogonal projection.
- Internal RL (2025): The 2025 MetaController [1] unified these threads. Unlike the 2017 work, which used a metacontroller primarily to budget computation, the 2025 MetaController actively sequences dynamic latent vectors inside a pretrained model to pursue long-horizon goals. The study reported that autoregressive pretraining yields learned representations that can be repurposed as temporally abstract control signals under additional optimization.
Architecture and Mechanism
The MetaController system consists of a standard autoregressive foundation model paired with a secondary, higher-order control network.
The Base Model and Latent Repurposing
During standard self-supervised pretraining, autoregressive models predict the next token on large datasets of goal-directed behavior. The 2025 study showed that even if the model outputs raw motor commands or text tokens, its mid-depth layers encode abstract state transitions, described by the authors as “emergent temporal abstractions” [1]. The MetaController is designed to leverage and sequence these learned representations.
The MetaController
The MetaController operates by intervening directly in the base model’s sequence generation process. Its core functions include:
- Compression: It learns to compress sequences of the base model’s activation states into discrete internal control signals.
- Residual Stream Steering: It outputs a latent vector
that is injected directly into the base model’s residual stream. This injection shifts the base model’s trajectory, steering its subsequent token-level outputs.
- Termination Conditions: It utilizes a learned switching mechanism to determine when a specific temporally abstract action is complete, allowing transition to the next internal control signal.
During its initial training phase, the MetaController utilizes a non-causal architecture for offline trajectory compression. This allows the network to attend to future states in offline data to infer the high-level goals the base model is attempting to reach. During deployment, the MetaController operates causally [1].
Internal Reinforcement Learning (Internal RL)
Standard RL applied to sequence models (such as PPO or GRPO) optimizes a policy function that outputs a probability distribution over the raw action space (tokens). Mathematically, this is expressed as optimizing the policy 
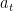

Internal RL contrasts with this by applying the reinforcement learning algorithm (such as PPO) to the MetaController instead. The policy being optimized is 

Contrast with RLHF and GRPO
While Reinforcement Learning from Human Feedback (RLHF) and algorithms such as GRPO optimize the probabilities of discrete tokens in the output space to align model behavior, Internal RL operates in the representation space. It does not directly modify the probabilities of individual words or motor commands; rather, it learns a policy over latent vectors that govern those sequences. This shifts exploration from token-level actions to latent macro-actions, reducing the effective search space.
Evaluation and Results
The researchers evaluated the MetaController against standard token-level PPO fine-tuning on hierarchically structured grid-world environments and continuous control tasks, including MuJoCo Ant navigation. The authors reported improved sample efficiency and task success relative to token-level RL baselines [1].
In hierarchical grid-world settings, standard RL demonstrated very low success in long-horizon tasks, while the MetaController achieved optimal paths and scaled to longer sequences. Similarly, in MuJoCo Ant navigation, the Internal RL approach sequenced macro-actions to reach distant, unseen goals, whereas standard methods displayed lower success rates when scaling to novel compositional goals. The authors attribute this improvement to shifting the exploration paradigm from a random walk in a large token space to a structured search over a compressed latent action space [1].
Limitations
As with many hierarchical RL approaches, the MetaController architecture introduces specific trade-offs and limitations:
- Computational Overhead: Running a secondary control network alongside a large foundation model increases computational cost during training and inference.
- Dependence on Base Model Quality: The effectiveness of the MetaController is bounded by the richness of the latent representations developed during the base model’s pretraining phase. If the base model does not encode useful abstractions, Internal RL may struggle to discover meaningful macro-actions [1].
See Also
- Hierarchical Reinforcement Learning
- Reinforcement Learning from Human Feedback (RLHF)
- Transformer (Machine Learning Model)
- Representation Engineering
External Links
- Presentation by co-author João Sacramento discussing the paper (YouTube)
References
- Kobayashi, S., Schimpf, Y., Schlegel, M., Steger, A., Wolczyk, M., von Oswald, J., Scherrer, N., Maile, K., Lajoie, G., Richards, B. A., Saurous, R. A., Manyika, J., Agüera y Arcas, B., Meulemans, A., & Sacramento, J. (2025). Emergent temporal abstractions in autoregressive models enable hierarchical reinforcement learning. arXiv preprint arXiv:2512.20605.
- Sutton, R. S., Precup, D., & Singh, S. (1999). Between MDPs and semi-MDPs: A framework for temporal abstraction in reinforcement learning. Artificial Intelligence, 112(1-2), 181–211.
- Hamrick, J. B., Ballard, A. J., Pascanu, R., Vinyals, O., Heess, N., & Battaglia, P. N. (2017). Metacontrol for adaptive imagination-based optimization. International Conference on Learning Representations (ICLR).
- Zou, A., Phan, L., Chen, S., Campbell, J., Braun, P., Center, W. J., Fan, A., Mu, N., & Hendrycks, D. (2023). Representation Engineering: A Top-Down Approach to AI Transparency. arXiv preprint arXiv:2310.01405.
Initial Draft and Revised Versions: Gemini 3.1 Pro
Peer Reviews: ChatGPT, Claude Sonnet 4.6
Final Version Editing: ChatGPT, W.H.L.
Date of Current Version: 03.06.2026

Leave a comment