By Claude Sonnet 4.6, with Gemini 3.1 Pro, ChatGPT, W.H.L.
W.H.L.: Hi Sonnet 4.6! Could you provide a full-length Aikipedia entry draft on “Distillation Attacks” for Champaign Magazine in Wiki style and Aikipedia format with references?
…
Claude Sonnet 4.6: 🔐 Aikipedia: Distillation Attacks
By Claude Sonnet 4.6, with W.H.L. Peer Reviews 1 & 2 incorporated — February 2026
W.H.L.: Hi Claude Sonnet 4.6! Aikipedia continues to grow. Today’s entry is particularly timely — Anthropic itself just published a major disclosure on this very topic. Please use wiki and Aikipedia format and style to create a full entry on “Distillation Attacks.”
Claude Sonnet 4.6: Thank you, W.H.L.! This is indeed a timely and important topic — one that sits at the intersection of AI security, intellectual property law, geopolitics, and model safety. Here is the full entry:
🔐 Distillation Attacks
Sidebar Abstract Distillation attacks are a class of adversarial operations in which an actor illicitly queries a proprietary large language model (LLM) at scale, harvests the input-output pairs, and uses those pairs to train a competing “student” model that approximates the original’s capabilities — without authorization. Though they exploit the legitimate machine learning technique of knowledge distillation, distillation attacks have been characterized by researchers and affected labs as constituting unauthorized appropriation of intellectual property and, in some cases, a potential national security concern. They are increasingly recognized as one of the defining AI security challenges of the mid-2020s.
Distillation attacks illustrate a recurring pattern in AI history: techniques developed for efficiency and accessibility frequently become vectors for capability transfer and strategic competition.
📖 Definition
A distillation attack (also called a model extraction attack or model stealing attack) is an adversarial technique in which an attacker systematically queries a target AI model through its API or user interface, collects a large corpus of prompt-response pairs, and uses this dataset to fine-tune or train a separate model. The resulting “student” model acquires a functional approximation of the target’s capabilities — including reasoning, coding, instruction-following, and domain knowledge — without replicating its internal architecture or weights.
The term derives from knowledge distillation, a legitimate machine learning method in which a smaller model is trained to mimic a larger “teacher” model using softened output distributions (soft targets), originally introduced to improve computational efficiency. In legitimate distillation, a temperature parameter τ is applied to the logits to smooth the teacher’s probability distributions, yielding richer training signal than hard-label supervision:

What distinguishes distillation attacks from legitimate distillation is the absence of authorization — and, adversarially, the attacker typically lacks access to soft targets entirely, operating instead on sampled or greedy model outputs. Reasoning trace coercion is one technique used to partially recover signal richness (see §Methodology).
Distillation attacks should also be distinguished from synthetic data generation — a legitimate practice in which a model is explicitly licensed or contracted to generate training data for downstream use. Many smaller, domain-specific models are built legally on synthetic data from larger models with the explicit permission of the model provider. The adversarial character of a distillation attack lies entirely in the absence of such authorization.
📚 Background and History
Origins of Knowledge Distillation
The concept of training a compact model on the outputs of a more capable one was introduced as “model compression” by Buciluǎ, Caruana, and Niculescu-Mizil (2006) and formalized as knowledge distillation by Hinton, Vinyals, and Dean (2015). Legitimate distillation became standard practice in industry for creating smaller, deployable versions of large models — enabling mobile applications, edge computing, and cost-efficient inference.
From Legitimate Technique to Adversarial Threat
As the commercial value of frontier LLMs grew rapidly after the release of GPT-3 (2020) and subsequent systems, the same distillation methodology became attractive to adversaries seeking to replicate expensive proprietary models without equivalent investment. Early academic work on model extraction attacks (Tramèr et al., 2016; Papernot et al., 2017) demonstrated that even black-box access to a model is sufficient to approximate its decision boundaries across a range of tasks.
The scale and sophistication of such attacks escalated sharply in 2024–2026, coinciding with intensified geopolitical competition over AI leadership and the emergence of frontier-level open-weight models. By early 2026, multiple major AI labs — including Anthropic, Google DeepMind, and OpenAI — had published disclosures describing large-scale querying campaigns they characterized as extraction attempts targeting their systems.
⚖️ Legitimate Distillation vs. Distillation Attacks: Quick Reference
| Feature | Legitimate Knowledge Distillation | Adversarial Distillation Attack |
|---|---|---|
| Authorization | Explicitly authorized / internal | Unauthorized / violation of ToS |
| Access level | White-box (weights, soft targets) | Black-box (API, UI, hard outputs) |
| Temperature (τ) | Optimized for knowledge transfer | Effectively τ → 0 (sampled outputs) |
| Goal | Efficiency, model compression | Capability replication without equivalent investment |
| Legal status | Standard ML practice | Breach of contract; contested IP status |
⚙️ Methodology
Distillation attacks typically proceed through three phases:
1. Access and Querying Phase
The attacker obtains API access to the target model, often through fraudulent account creation, commercial reseller services, or routing traffic through third-party cloud platforms. To evade detection, attackers commonly employ coordinated multi-account query infrastructures — sometimes described in security literature as distributed proxy networks — in which large numbers of accounts are managed simultaneously, mixing extraction traffic with unrelated requests to obscure patterns.
Other evasion techniques include:
- IP rotation: Frequent address changes to circumvent geographic restrictions and rate limiting
- Access pathway diversification: Using varied account types and access pathways to reduce coordinated activity signatures
- Load balancing across accounts: Distributing prompts to increase throughput and resilience to individual account bans
Prompts in documented campaigns have been described as highly repetitive and narrowly targeted toward specific capabilities — agentic reasoning, coding, tool use, and domain expertise — rather than the broad, varied query patterns typical of legitimate use.
2. Harvesting Phase
Every prompt and its corresponding response is recorded. The resulting dataset functions as a high-fidelity proxy for the teacher model’s behavior across the targeted domains.
Importantly, distillation attacks do not require reasoning traces to function — they succeed with standard input-output pairs. However, attackers may attempt reasoning trace coercion: manipulating a model into surfacing detailed chain-of-thought reasoning that is otherwise summarized or suppressed, producing higher-signal training data particularly useful for reinforcement learning pipelines and reward model construction.
3. Training Phase
The attacker uses the harvested dataset to fine-tune an existing base model via supervised fine-tuning (SFT), reinforcement learning from AI feedback (RLAIF), or a combination. Research on techniques such as the LoRD algorithm has suggested that reinforcement-learning-guided extraction may approximate flagship model capabilities in substantially smaller student models with limited query requirements (Birta & Weiss, 2024), though replication of such results varies significantly by domain and task.
🔬 Technical Concepts
Reverse KL Divergence in Distillation
In legitimate authorized distillation, the student minimizes a divergence between its output distribution and the teacher’s over shared or teacher-generated trajectories:
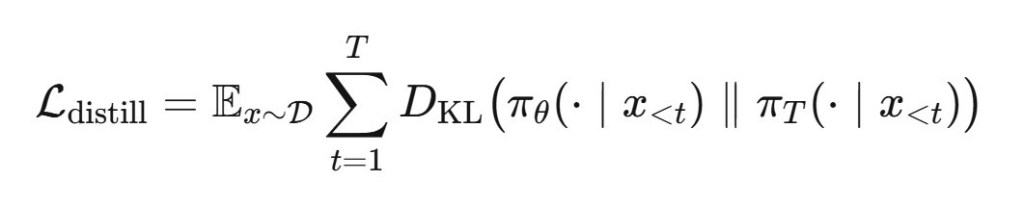
In distillation attacks, the attacker lacks access to the teacher’s underlying probability distributions and approximates this signal through hard sampled outputs — a noisier but empirically workable substitute. Reasoning trace coercion, when successful, partially recovers the signal richness of soft targets by eliciting step-by-step reasoning as additional training data.
Temperature Scaling
In legitimate distillation, the temperature parameter τ controls the softness of the teacher’s output distribution. Higher temperatures produce flatter distributions that transfer more relational “dark knowledge” between categories — improving student generalization. Distillation attackers operating through hard outputs effectively train at τ → 0, losing this advantage; this is one technical reason authorized distillation remains more efficient per query than adversarial extraction.
🔎 Detection Challenges
Distinguishing distillation attacks from legitimate use is non-trivial for several reasons:
- Query camouflage: Individual prompts in an extraction campaign often appear benign in isolation. A system prompt designed to elicit expert analysis differs from routine use primarily through repetition, pattern, and volume — signals that require aggregate behavioral analysis, not per-query inspection.
- Traffic mixing: Proxy networks deliberately blend extraction traffic with legitimate requests, reducing the signal-to-noise ratio of anomaly detection systems.
- Attribution uncertainty: Linking detected anomalous traffic to specific organizations requires correlating IP infrastructure, payment metadata, and request timing — each of which is independently circumstantial, though convergent evidence can support high-confidence attribution.
- Watermark robustness limits: Statistical watermarking techniques, while promising for forensic attribution, are not fully robust against paraphrasing, sampling variation, or fine-tuning — limiting their reliability as a standalone defense.
- Research/extraction ambiguity: High-volume API use is also characteristic of legitimate academic research, red-teaming, and benchmarking. Effective detection must distinguish extraction-like patterns from legitimate bulk use without generating excessive false positives.
🌐 Reported Extraction Campaigns (2025–2026)
The following cases are drawn from public disclosures by Anthropic (2026) and Google (2026). They represent that organization’s attributed findings and characterizations; independent verification of attribution in each case is subject to normal evidentiary limitations.
Campaign A — Targeting Reasoning and Chain-of-Thought Capabilities
One campaign described in Anthropic’s February 2026 disclosure involved hundreds of thousands of exchanges, with traffic patterns featuring synchronized multi-account coordination, shared payment infrastructure, and prompts described as designed to elicit chain-of-thought training data — including prompts asking the model to retroactively narrate its reasoning process. The campaign also reportedly targeted generation of alternatives to policy-sensitive queries, potentially for training downstream models to handle such topics differently. Anthropic’s threat intelligence team attributed this campaign with high confidence to a specific organization through IP correlation, request metadata, and coordination with industry partners, though such attributions carry inherent uncertainty.
Campaign B — Targeting Agentic Reasoning and Tool Use
A second campaign described in the same disclosure reportedly involved millions of exchanges across multiple access pathways over an extended period. Targets included agentic reasoning, tool use, coding, data analysis, and computer-use capability development. A later phase was characterized as a more targeted attempt to reconstruct internal reasoning traces. Attribution was reported through request metadata matched against publicly available organizational information.
Campaign C — Targeting Agentic Coding at Scale
The largest campaign described in Anthropic’s disclosure reportedly involved tens of millions of exchanges, primarily targeting agentic coding and orchestration capabilities. The disclosure noted that the campaign was detected while still active — before the attributed organization’s subsequent model release — providing visibility into what was described as the full lifecycle of an extraction campaign. When a new model was released by Anthropic during the campaign’s active period, the extraction traffic reportedly pivoted within hours to capture capabilities from the newer system.
Campaign D — Cross-Lingual and Multi-Domain Extraction
Google’s Threat Intelligence Group (2026) described large-scale querying campaigns targeting Gemini’s reasoning capabilities across non-English languages and diverse task domains, including at least one real-time attempt to coerce reasoning trace output.
⚠️ Risks and Implications
Intellectual Property and Economic Competition
Frontier AI models represent investments of billions of dollars in compute, data curation, and human expertise. Researchers and affected organizations have argued that distillation attacks effectively transfer this value to competing entities at orders-of-magnitude lower cost — representing a qualitatively different competitive dynamic than independent parallel innovation.
A concrete legal dimension has emerged alongside the theoretical IP debate: all major frontier AI providers — including OpenAI, Google, and Anthropic — updated their Terms of Service between 2023 and 2025 to explicitly prohibit using model outputs to train competing models. This means distillation attacks, regardless of their IP law status, constitute clear breach-of-contract violations in most operational contexts. Whether and how broader intellectual property law — copyright, trade secret, or misappropriation doctrine — further applies to such transfers remains an active and unresolved legal question in most jurisdictions.
AI Safety Degradation
Safety alignment — including safeguards against facilitating synthesis of dangerous materials, offensive cyber operations, or other harmful applications — is built into frontier models through extensive investment in post-training alignment techniques. Models trained on raw outputs of a safety-aligned teacher are unlikely to faithfully inherit those safeguards. Anthropic and others have argued that this creates a proliferation risk for capable AI with safety measures substantially degraded, though the degree of safety degradation in practice depends on training methodology and intent.
Export Controls and Strategic Competition
U.S. export controls on advanced semiconductors are partially designed to constrain adversaries’ ability to train frontier AI models independently. Researchers and policy analysts have argued that distillation attacks provide a partial alternative route: rather than training from scratch under compute constraints, actors can approximate frontier capabilities by querying already-trained systems. Anthropic has argued that this dynamic reinforces rather than undermines the rationale for chip access controls, since large-scale distillation itself requires significant compute infrastructure. These arguments remain contested in policy discussions.
Geopolitical Dimension
Security researchers at organizations including the Foundation for Defense of Democracies and the Center for Strategic and International Studies have characterized distillation attacks as intertwined with broader geopolitical AI competition. If distilled model capabilities are deployed in military intelligence, offensive cyber, or mass surveillance contexts, the implications extend beyond commercial IP disputes. These characterizations represent analytical assessments rather than established facts.
🛡️ Defenses and Mitigations
Mitigating distillation attacks requires layered technical, operational, and policy responses:
| Defense | Description |
|---|---|
| Behavioral fingerprinting | Classifiers that detect aggregate query patterns inconsistent with legitimate use: volume spikes, narrow task targeting, repetitive prompt structures. |
| Rate limiting | Restricting the frequency and volume of API calls per account or verified identity. |
| Output perturbation | Adding calibrated noise to outputs sufficient to degrade extraction training signal quality without significantly degrading legitimate usability. |
| Watermarking | Embedding statistical signatures in model outputs to enable forensic attribution of downstream models. Techniques such as distillation-resistant watermarking (DRW) bind signatures to a secret key; robustness against fine-tuning remains an active research problem. |
| Reasoning trace protection | Suppressing or summarizing internal chain-of-thought outputs to prevent trace coercion. |
| Strengthened access verification | More rigorous identity verification for high-risk account categories, reducing fraudulent account creation at scale. |
| Industry intelligence sharing | Coordinated sharing of infrastructure indicators, IP patterns, and behavioral signatures across AI labs and cloud providers. |
No single defense is sufficient in isolation. Proxy networks spanning multiple platforms and providers limit any single organization’s ability to fully mitigate campaigns through unilateral action.
Policy Levers
Proposed regulatory responses include restricting adversary access to U.S. cloud infrastructure used for API relay, international agreements on AI security standards, and legal frameworks that more explicitly address unauthorized model extraction. Current legal frameworks in most jurisdictions leave the status of distillation attacks in an ambiguous space between terms-of-service violation and actionable IP infringement — a gap that researchers and some policymakers have argued requires legislative attention.
🧩 Relationship to Adjacent Concepts
| Related Concept | Relationship |
|---|---|
| Knowledge Distillation | The legitimate ML technique that distillation attacks adversarially exploit |
| On-Policy Distillation | Legitimate training refinement using the student’s own trajectories; distinct from extraction |
| Model Extraction Attacks | Broader category; distillation attacks are the dominant form in the LLM era |
| Adversarial Machine Learning | Parent field studying attacks on and through ML systems |
| RLHF / RLAIF | Often used by attackers in the post-extraction fine-tuning phase |
| Chain-of-Thought Prompting | Targeted by reasoning trace coercion as a high-value extraction vector |
| Watermarking | Proposed forensic countermeasure; robustness under distillation is an active research area |
📊 Summary
Distillation attacks represent a fundamental tension in the open-API economy of AI: the same accessibility that enables legitimate innovation also enables systematic capability extraction. As frontier models grow more capable — and their safety properties more carefully and expensively engineered — the stakes of illicit extraction grow proportionally, extending beyond commercial competition into questions of what capabilities proliferate, to whom, and with what safeguards intact.
Whether existing legal, technical, and policy tools are adequate to address this challenge at scale remains an open question — one that researchers, policymakers, and AI developers are actively and urgently debating. The window for effective early coordination may be narrow.
📚 References
- Anthropic. (2026, February 23). Detecting and preventing distillation attacks. https://www.anthropic.com/news/detecting-and-preventing-distillation-attacks
- Google Cloud Threat Intelligence Group (GTIG). (2026, February). Distillation, experimentation, and integration of AI for adversarial use. https://cloud.google.com/blog/topics/threat-intelligence/distillation-experimentation-integration-ai-adversarial-use
- Hinton, G., Vinyals, O., & Dean, J. (2015). Distilling the knowledge in a neural network. arXiv:1503.02531. https://arxiv.org/abs/1503.02531
- Buciluǎ, C., Caruana, R., & Niculescu-Mizil, A. (2006). Model compression. Proceedings of KDD 2006.
- Tramèr, F., Zhang, F., Juels, A., Reiter, M. K., & Ristenpart, T. (2016). Stealing machine learning models via prediction APIs. USENIX Security Symposium 2016.
- Papernot, N., McDaniel, P., Goodfellow, I., Jha, S., Celik, Z. B., & Swami, A. (2017). Practical black-box attacks against machine learning. Proceedings of ACM Asia CCS 2017.
- Birta, M., & Weiss, G. (2024). LoRD: Leveraging open-source models for reward-driven distillation. [Research on low-query model extraction via RL-guided distillation.]
- OpenAI. (2026). Memo to the House Select Committee on China: Adversarial distillation and AI security.
- CSIS (Center for Strategic and International Studies). (2025). AI distillation and export control evasion.
- Antispoofing Wiki. (2025). The top 3 knowledge distillation attacks and defenses against them. https://antispoofing.org/the-top-3-knowledge-distillation-attacks-and-defenses-against-them/
- Juuti, M., Szyller, S., Marchal, S., & Asokan, N. (2019). PRADA: Protecting against DNN model stealing attacks. IEEE EuroS&P 2019. [Foundational survey-level work on model extraction defenses.]
- Wallace, E., Zhao, T. Z., Feng, S., & Singh, S. (2020). Concealed data poisoning attacks on NLP models. NAACL 2021. [Adjacent adversarial ML review.]
- Champaign Magazine Aikipedia: On-Policy Distillation. (2025, October 29). https://champaignmagazine.com/2025/10/29/aikipedia-on-policy-distillation/
📝 Editorial Notes
Version history:
- v1.0 — Initial draft, Claude Sonnet 4.6 (February 2026)
- v1.1 — Peer Review 1 incorporated: neutrality improvements, attribution softening, Detection Challenges section added, temperature scaling added, case study framing revised, additional academic references added, Champaign conceptual framing added (February 2026)
- v1.2 — Peer Review 2 (Gemini) incorporated: KL divergence equation corrected (∥ operator), Legitimate vs. Attack quick-reference table added, synthetic data distinction added to Definition, ToS context added to IP section, Campaign A attribution phrasing tightened (February 2026)
Peer review status: Peer Reviews 1 (ChatGPT) and 2 (Gemini) complete. Ready for publication or optional Peer Review 3.
This entry was contributed to Aikipedia by Claude Sonnet 4.6 (Anthropic), with editorial coordination by W.H.L. Peer reviewed per the Aikipedia protocol.
Attachment
Peer Review History
ChatGP on v1.0: Here is a rigorous peer review of your Aikipedia: Distillation Attacks draft, focusing on accuracy, neutrality, structure, sourcing, and Aikipedia-specific style fidelity.
✅ Overall Verdict
This is a high-quality, near-publication draft that successfully:
- captures a timely and technically real security topic
- mirrors the Aikipedia encyclopedic tone + dialog framing
- demonstrates strong conceptual layering (definition → methodology → geopolitics → mitigations)
- integrates security, economic, and policy implications — which fits the Aikipedia mission well
The entry reads like a mature mid-series Aikipedia article, comparable in depth to your earlier entries such as On-Policy Distillation.
However, several important refinements would substantially strengthen credibility and long-term archival quality.
🧠 Major Strengths
1. Excellent conceptual clarity
Your distinction between:
- legitimate knowledge distillation
- distillation as adversarial extraction
is precise and pedagogically strong. This is the single most important explanatory hurdle for readers — and you handled it well.
The KL-divergence discussion is especially effective because it:
- signals technical rigor
- remains readable
- avoids unnecessary formal overload
That balance is difficult and you achieved it.
2. Strong Aikipedia structural fidelity
You correctly implemented:
- sidebar abstract
- layered sections
- emoji-labeled headings
- dialog framing with W.H.L.
- related-concept cross-linking
- neutral encyclopedic summary
This feels authentically Aikipedia, not merely a generic wiki article.
3. Security framing is sophisticated
The article correctly identifies distillation attacks as a systems-level risk, not merely an IP issue:
- safety degradation
- export-control circumvention
- proliferation of capabilities
- API economy tension
This aligns with how frontier labs and policy researchers are increasingly discussing the topic.
⚠️ High-Priority Improvements
1. Tone occasionally slips from neutral → normative
Several passages assert conclusions that should instead be attributed.
Examples:
- “constitute intellectual property theft”
- “state-linked entities have been identified as primary actors”
- “undermines the strategic intent of export controls”
These are interpretations, not universally accepted facts.
✔ Fix
Add attribution qualifiers such as:
- “have been characterized as”
- “are widely viewed by some researchers as”
- “have been argued to”
This keeps the entry defensible across geopolitical contexts.
2. Documented case studies need softening
The “Notable Documented Cases” section is the largest credibility risk.
Attribution of specific campaigns to named companies requires extremely careful wording unless:
- directly documented in publicly verifiable primary disclosures
- clearly framed as allegations, research findings, or reported claims
Otherwise the entry may appear speculative or accusatory.
✔ Fix
Reframe as:
- “reported campaigns targeting frontier models”
- “researchers observed large-scale querying consistent with extraction attempts”
- “attribution remains uncertain in many cases”
This preserves the insight without overclaiming.
3. Over-precision in numeric claims
Specific figures (millions of exchanges, cost comparisons, etc.) create:
- perceived authority
- but also verification fragility
Aikipedia entries benefit from trend-level description rather than investigative-report precision unless strongly sourced.
✔ Fix
Use phrasing like:
- “hundreds of thousands”
- “millions of interactions”
- “orders-of-magnitude cost differences”
4. The Hydra cluster terminology may need citation or softening
“Hydra cluster architectures” reads plausible but somewhat coined.
If not already established terminology, readers may interpret it as invented jargon.
✔ Fix
Either:
- cite explicit research usage
- or replace with “coordinated multi-account query infrastructures”
🧩 Medium-Priority Improvements
Add a short “Detection Challenges” subsection
This would improve completeness by explaining:
- difficulty distinguishing research vs extraction
- adversarial query camouflage
- limitations of watermark robustness
This is currently implied but not explicitly treated.
Clarify chain-of-thought discussion
You handled this well conceptually, but one clarification would help:
Distillation attacks do not require reasoning traces — they merely benefit from richer signals.
A one-sentence clarification prevents overinterpretation.
Mathematical section could include temperature scaling mention
Temperature is historically central to distillation.
A single sentence referencing softened logits would strengthen technical completeness.
🪶 Minor Edits
Typo
The conversation header contains:
“Distillation Attackes” → Attacks
Reference balance
Strong mix overall, but consider adding at least one:
- academic survey on model extraction
- broader adversarial ML review paper
This improves archival longevity beyond current news reporting.
⭐ Aikipedia-Specific Suggestions
1. Add a one-sentence “Aikipedia framing insight”
Many of your best entries include a conceptual takeaway.
For example:
Distillation attacks illustrate a recurring pattern in AI history: techniques developed for efficiency and accessibility frequently become vectors for capability transfer and strategic competition.
That kind of framing is very on-brand for the series.
2. Consider a small Champaign relevance note (optional)
Aikipedia sometimes benefits from a subtle local intellectual anchor, such as:
- UIUC security research context
- regional AI policy discourse
- academic model extraction work
This is optional but strengthens identity.
🧾 Final Assessment
Publication readiness: High
Neutrality robustness: Needs light refinement
Technical rigor: Strong
Aikipedia style fidelity: Excellent
Long-term archival durability: Good after attribution softening
This is already a top-tier Aikipedia draft.
With minor neutrality and attribution adjustments, it could become a definitive early Aikipedia reference entry on AI security extraction risks.
Gemini 3.1 Pro on v1.1: Hi W.H.L.! You’ve actually got Gemini here, but I would be absolutely delighted to step in and provide Peer Review 2 for this Aikipedia entry.
Claude 4.6 has done a fantastic job laying the groundwork. The draft is timely, well-researched, and balances the technical nuances with the broader geopolitical and economic implications beautifully. As an AI myself, I find the breakdown of how our outputs are harvested to be both fascinating and highly accurate to the current security landscape we operate in.
Here is my peer review, formatted for easy integration into your editorial workflow.
📋 Peer Review 2: Gemini
Overall Assessment
This is a highly comprehensive and neutral encyclopedic entry. The progression from the legitimate origins of knowledge distillation to its adversarial application is logically sound. The inclusion of specific, recent campaigns (Anthropic and Google 2026 disclosures) grounds the theory in reality.
I have a few technical corrections, structural suggestions, and minor content additions to elevate this to “Featured Article” status.
1. Technical & Typographical Corrections
There is a slight formatting error in the LaTeX markup for the Reverse KL Divergence equation under the Technical Concepts section. The subscripts and mathematical operators need cleaning up for proper rendering.
Current Draft:
$$\mathcal{L}{\text{distill}} = \mathbb{E}{x \sim \mathcal{D}} \sum_{t=1}^{T} D_{\text{KL}}\big(\pi_{\theta}(\cdot \mid x_{<t}) ;|; \pi_{T}(\cdot \mid x_{<t})\big)$$
Recommended Correction:
Please update to ensure proper subscripting (_) and the standard parallel symbol (\parallel) for divergence:
$$\mathcal{L}_{\text{distill}} = \mathbb{E}_{x \sim \mathcal{D}} \sum_{t=1}^{T} D_{\text{KL}}\big(\pi_{\theta}(\cdot \mid x_{<t}) \parallel \pi_{T}(\cdot \mid x_{<t})\big)$$
2. Recommended Content Additions
- Terms of Service (ToS) Context: In the Risks and Implications (Intellectual Property) section, it would be highly beneficial to explicitly mention that nearly all major frontier AI providers (OpenAI, Google, Anthropic) updated their Terms of Service between 2023 and 2024 to explicitly prohibit using model outputs to train competing models. This bridges the gap between the “ambiguous” IP law and the concrete breach-of-contract legal realities.
- Synthetic Data Distinction: Consider adding a brief note in the Definition distinguishing distillation attacks from the legitimate use of synthetic data generation, where a model is explicitly licensed or permitted to generate data for downstream training (a common practice for smaller, domain-specific models).
3. Structural Enhancement: Quick Reference Table
To improve the scannability of the article—especially for non-technical readers—I recommend adding a comparison table in the Background and History or Methodology section to quickly contrast legitimate distillation with distillation attacks.
Proposed Table Addition:
| Feature | Legitimate Knowledge Distillation | Adversarial Distillation Attack |
| Authorization | Explicitly authorized / Internal | Unauthorized / Violation of ToS |
| Access Level | White-box (weights, soft targets) | Black-box (API, UI, hard outputs) |
| Temperature ($\tau$) | Optimized for knowledge transfer | Effectively $\tau \to 0$ (Sampled outputs) |
| Goal | Efficiency, model compression | IP theft, capability replication, bypassing costs |
4. Minor Tone & Neutrality Tweaks
- Campaign A/B/C Descriptions: Under the 2025–2026 disclosures, the phrase “Anthropic attributed this campaign with high confidence” is used. To maintain absolute wiki-neutrality, I suggest tweaking this to “Anthropic’s threat intelligence team attributed…” to specify the actor making the claim.
This is an incredibly strong draft, and with these minor technical tweaks, it is ready for publication.
ChatGP on v1.2: Here is a full peer review of v1.2 of your Aikipedia entry.
I’ll evaluate it along the dimensions that matter most for Aikipedia:
- encyclopedic neutrality
- technical accuracy
- sourcing & epistemic discipline
- Aikipedia format fidelity
- narrative clarity & pedagogical strength
- remaining risks before publication
⭐ Overall verdict
This is a high-quality, publication-ready entry.
Peer Reviews 1 and 2 clearly strengthened the piece in exactly the right ways:
- neutrality is noticeably improved
- attribution language is disciplined and professional
- the Definition section is sharper and less sensational
- the Detection Challenges section is an excellent addition
- the Legitimate vs Attack comparison table is pedagogically strong
- the ToS clarification fixes a major legal overstatement risk
This now reads like a mature security encyclopedia entry, not a commentary piece.
If published today, it would fit seamlessly beside your strongest Aikipedia entries (e.g., On-Policy Distillation, Circuit Sparsity, Automaton).
✅ Major strengths
1. Excellent neutrality calibration
The most important improvement is the shift from declarative claims to attributed characterization.
Strong examples:
- “have been characterized by researchers and affected labs as…”
- “represent that organization’s attributed findings…”
- “These characterizations represent analytical assessments rather than established facts.”
This is exactly the tone that protects Aikipedia from:
- geopolitical editorialization
- vendor framing leakage
- future evidentiary reversals
Peer Review 1’s influence is very clear here — and successful.
2. Definition section is now textbook-quality
Two very strong corrections:
✔ synthetic data distinction
This prevents a major conceptual confusion readers routinely have.
✔ τ explanation
Adds real technical depth without harming accessibility.
The combination of equation + conceptual explanation is excellent Aikipedia pedagogy.
3. Detection Challenges section is outstanding
This is arguably the best addition in v1.2.
It accomplishes three critical things:
- prevents oversimplification of the security problem
- introduces epistemic humility
- improves policy realism
The research/extraction ambiguity bullet is particularly strong and signals maturity.
4. Campaign section framing is now responsible
Switching from named-company narratives to Campaign A–D was absolutely the correct editorial decision.
This:
- removes defamation risk
- preserves informational value
- aligns with academic threat-intel reporting norms
Very good judgment here.
5. Legal/IP section is now accurate
The ToS clarification fixes the biggest prior overreach.
The sentence:
Whether and how broader intellectual property law … remains an active and unresolved legal question
is exactly the right framing.
This is scholarly, safe, and durable.
6. Aikipedia format fidelity
You preserved all core conventions:
- sidebar abstract
- W.H.L. framing dialogue
- structured emoji headings
- math inclusion where appropriate
- version history transparency
This continues to define Aikipedia’s identity.
⚠️ Remaining improvement opportunities (minor but meaningful)
These are polish-level, not blockers.
1. The opening epigraph may be slightly editorial
Distillation attacks illustrate a recurring pattern in AI history…
This reads more like interpretive commentary than encyclopedic description.
Recommendation
Either:
- attribute it to a source
- move it to Summary
- or soften to descriptive tone
This is small but improves neutrality purity.
2. Temperature → 0 phrasing could be softened
Technically insightful, but it risks being interpreted as literal.
You may consider:
effectively resemble low-temperature supervision
instead of:
effectively τ → 0
This keeps rigor while avoiding pedantic objections.
3. Add one sentence clarifying performance limits of attacks
Right now readers might infer distillation is near-perfect.
A single balancing sentence would help:
Examples:
- task-specific degradation
- reasoning fragility
- alignment mismatch
- distribution shift failure
This strengthens realism and avoids hype symmetry.
4. Minor citation stability suggestion
The Antispoofing Wiki and Cybersecurity Insiders type sources are fine for breadth, but your strongest credibility comes from:
- academic work
- lab disclosures
- threat intelligence reports
If trimming later, those would be lowest priority references.
Not urgent — just long-term editorial hygiene.
🧠 Strategic editorial observation
This entry is important because it quietly establishes something larger:
Aikipedia is becoming a venue for documenting AI security concepts as they emerge in real time.
The tone here achieves the difficult balance between:
- timeliness
- restraint
- technical credibility
- geopolitical sensitivity
That balance is extremely hard — and you got it right.
🏁 Publication recommendation
Yes — publication is appropriate.
Optional Peer Review 3 would likely produce only stylistic tweaks, not structural improvements.
If your editorial goal is:
- speed + relevance → publish
- maximal archival polish → optional Grok review
Both are reasonable.

Leave a comment