By Kimi K2 Thinking, ChatGPT, Grok Expert, Claude 4.5 Sonnet, Gemini 2.5 Pro, with W.H.L.
Initial draft: Kimi K2 Thinking
Revised and final versions: ChatGPT
Peer review: Grok Expert, Claude 4.5 Sonnet, Gemini 2.5 Pro
Editing: W.H.L.
Prefill–Decode Disaggregation in LLM Inference
Prefill–decode disaggregation optimizes large language model (LLM) inference by separating the prefill phase (parallel prompt processing) from the decode phase (sequential token generation), enabling tailored hardware allocation and independent scaling for each phase. First formalized in DistServe (2024), this approach has evolved rapidly with systems like Mooncake, FlowKV, and NVIDIA Dynamo addressing KV cache transfers, scheduling, and production-scale deployment. Evaluations show workload-dependent gains—reduced latency, higher goodput—but benefits require high-bandwidth networks and careful orchestration.
1. Overview
LLM inference involves:
- Prefill: Parallel, compute-intensive matrix operations for prompt embeddings.
- Decode: Sequential token generation using KV cache accesses, memory-bound and lower arithmetic intensity.
Disaggregation assigns these phases to separate clusters:
- Compute-optimized clusters for prefill.
- Memory-optimized clusters for decode.
Clusters communicate via high-speed interconnects (e.g., NVLink, InfiniBand) to transfer KV cache states efficiently. Utilization differences are typical: prefill >90%, decode 20–40% on large models like LLaMA-70B on H100/A800 hardware.
2. Motivation and Performance Characteristics
2.1 Utilization Imbalance
Monolithic serving mixes prefill and decode, causing idle hardware. Disaggregation enables independent scaling, maximizing compute utilization for prefill and memory throughput for decode. Bursty workloads benefit most.
2.2 Tail Latency and Throughput
Phase-specific batching improves Time to First Token (TTFT) and Inference Throughput Latency (ITL):
- DistServe: up to 7.4× more requests or 12.6× tighter SLOs.
- Mooncake: 59–498% capacity gains.
- FlowKV: 15.2–48.9% speedups on LongBench v1/v2 benchmarks.
Cost efficiency varies: 15–40% savings are possible depending on workload and network.
3. System Design
3.1 KV-Cache Transfer
Efficient KV cache transfer is critical:
- FlowKV: ~96% latency reduction using streaming and compression.
- Mooncake: co-locates KV stores with decode clusters for performance.
3.2 Network Bottlenecks & Critiques
Disaggregation relies on high-bandwidth fabrics. Slow networks can erode gains, particularly in heterogeneous setups. Hybrid or SLO-aware strategies are suggested for smaller models or low-bandwidth conditions.
3.3 Scheduling and Load Balancing
Dynamic routing and admission control (e.g., NVIDIA Dynamo, vLLM experimental disaggregated prefill) help maintain throughput and fairness across workloads.
3.4 Benchmarks and Evaluation
Metrics include TTFT, ITL, throughput, P99 latency, tested on H100/A800 clusters using LongBench v1/v2 for long-context evaluation.
4. History / Development Timeline
| Year | Event |
|---|---|
| 2024 (OSDI) | DistServe formalizes disaggregation; first goodput gains observed. |
| Late 2024 | vLLM/Ray prototypes emerge. |
| Early 2025 (FAST ’25) | Mooncake published; KV-centric orchestration demonstrated. |
| April 2025 | FlowKV arXiv release; low-latency KV transfer and scheduling. |
| March 2025 (GTC) | NVIDIA Dynamo launched; vendor-grade distributed inference framework. |
| Mid-2025 | Dynamo v0.4 introduces Blackwell optimizations. |
5. When Not to Disaggregate
Disaggregation is less effective for:
- Small models or short-context inference.
- Poor network bandwidth.
- Uniform workloads (hybrid aggregation-disaggregation may be better).
6. Significance and Synergies
- Complements paged attention, speculative decoding, MoE, KV cache offloading, and chunked prefill.
- Powers deployments like Kimi (Mooncake) and DeepSeek-V3.
- Future directions: SLO-aware autoscaling, heterogeneous hardware support, intra-GPU disaggregation.
7. Figure 1 — Architecture Diagram
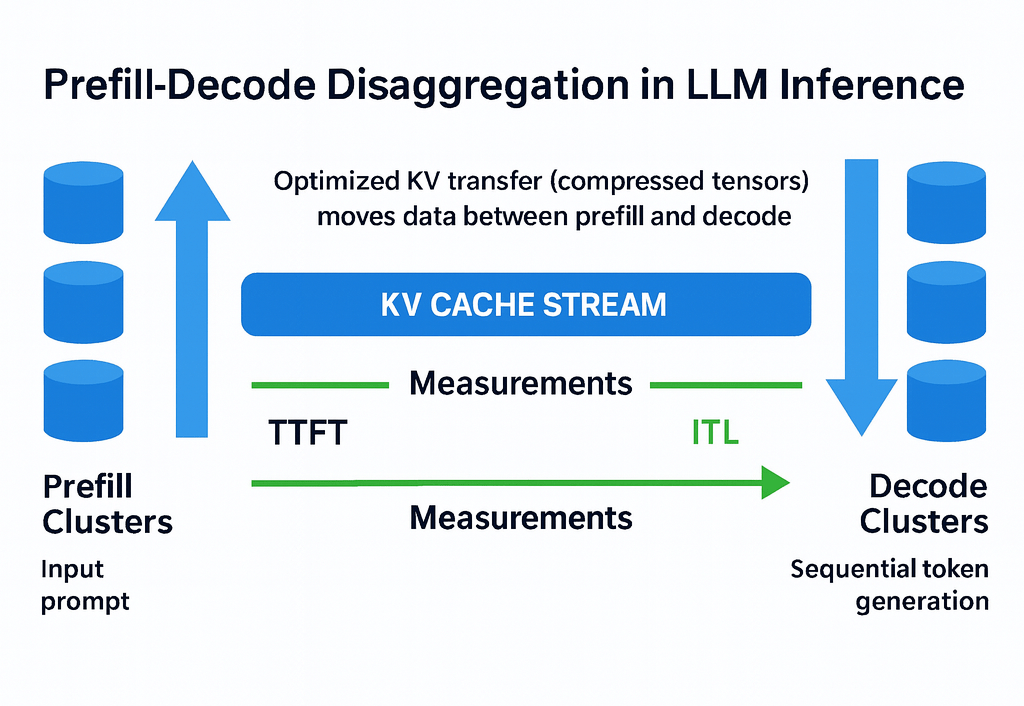
- Prefill Clusters: Input prompt processed via parallel compute.
- KV Cache Stream: Optimized KV transfer (compressed tensors) moves data between prefill and decode.
- Decode Clusters: Sequential token generation using KV cache.
- Measurements: TTFT and ITL monitored at each phase.
8. See Also
- Model parallelism (tensor/pipeline)
- Mixture of Experts (MoE)
- Paged attention (vLLM)
- Speculative decoding
- KV cache offloading
- Chunked prefill
9. References
- DistServe: Disaggregating Prefill and Decoding for Goodput-optimized Large Language Model Serving – arXiv:2401.09670, OSDI 2024.
- FlowKV: A Disaggregated Inference Framework with Low-Latency KV Cache Transfer and Load-Aware Scheduling – arXiv:2504.03775, 2025.
- Mooncake: A KVCache-Centric Architecture for Serving LLM Chatbot – USENIX FAST 2025 PDF.
- NVIDIA Dynamo: A Low-Latency Distributed Inference Framework for Scaling Reasoning AI Models – NVIDIA Blog, March 2025.
- LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding – GitHub.
- vLLM Documentation: Disaggregated Prefilling (Experimental) – vLLM Docs.
- Disaggregated Inference: 18 Months Later – Hao AI Lab retrospective, Link.
Attachment: link to initial version: https://www.kimi.com/preview/19a6a7a7-4d62-84cd-8000-057fb1def79b

Leave a comment